
In the previous post I have focused in avoiding as much as possible IO on disk and if that was not possible using buff/cache as much as possible by grouping in time IO operations. This approach can make our ETL processes run X times faster. In the two examples the numbers where:
- Avoiding IO at all was 11,3 times faster
- Using buff/cache was almost 4 times faster
All the examples used a dataset already in the disk so no real network operation occurred. In this post I am going to focus on network operation using again GNU parallel.
For this example we are going to use a different dataset containing stock ticks from megabolsa but hosted on my web server to avoid consume their bandwidth.
Files have been compressed using gzip to add some load to the process. There are 1276 files smaller than 3KB with a total size of 5.1M
find -type f |wc -l 1276 du -sh 5.1M .
Each file looks like this:
zmore 201103.txt.gz|head
A3M,20201103,2.25,2.328,2.25,2.304,285129
ACS,20201103,22.3,22.46,21.45,22.33,1404568
ACX,20201103,6.876,7.082,6.84,6.84,896128
You might think this is not a big data dataset but it is perfect to show how parallelization and other techniques can help with network operations to deal with small files and TCP slow start and congestion protocol. Let’s start!
Downloading the files in serial mode (-j1)
In this case we are going to feed the wget command with the complete urls using GNU parallel. The url is composed by a fixed part and a variable part depending year (two digits) month (to digits) and day of the month (two digits)
juan@mediacenter:~/elsotanillo$ time parallel -j1 wget -q https://www.elsotanillo.net/wp-content/uploads/parallel/{1}{2}{3}.txt.gz ::: `seq -w 16 20` ::: `seq -w 01 12` ::: `seq -w 01 31`
real 5m4,776s
user 0m10,564s
sys 0m14,806s
Which is 16.73 kB/s. This is going to be our baseline for the coming tests.
Downloading the files in parallel mode (using several cores combinations)
The server I am using for downloading has 4 cores. To check parallelization improvement I am going to uses several parallelization degree. From 4 jobs meaning one parallel job per core to 100 jobs meaning 25 parallel jobs per core. Here you are the results:
# 4 cores per wget url
juan@mediacenter:~/elsotanillo$ rm *
juan@mediacenter:~/elsotanillo$ time parallel -j4 wget -q https://www.elsotanillo.net/wp-content/uploads/parallel/{1}{2}{3}.txt.gz ::: `seq -w 16 20` ::: `seq -w 01 12` ::: `seq -w 01 31`
real 4m29,554s
user 0m10,379s
sys 0m14,736s
# 8 cores per wget url
juan@mediacenter:~/elsotanillo$ rm *
juan@mediacenter:~/elsotanillo$ time parallel -j8 wget -q https://www.elsotanillo.net/wp-content/uploads/parallel/{1}{2}{3}.txt.gz ::: `seq -w 16 20` ::: `seq -w 01 12` ::: `seq -w 01 31`
real 4m22,665s
user 0m9,902s
sys 0m14,707s
# 12 cores per wget url
juan@mediacenter:~/elsotanillo$ rm *
juan@mediacenter:~/elsotanillo$ time parallel -j12 wget -q https://www.elsotanillo.net/wp-content/uploads/parallel/{1}{2}{3}.txt.gz ::: `seq -w 16 20` ::: `seq -w 01 12` ::: `seq -w 01 31`
real 4m5,267s
user 0m9,819s
sys 0m15,080s
# 16 cores per wget url
juan@mediacenter:~/elsotanillo$ rm *
juan@mediacenter:~/elsotanillo$ time parallel -j16 wget -q https://www.elsotanillo.net/wp-content/uploads/parallel/{1}{2}{3}.txt.gz ::: `seq -w 16 20` ::: `seq -w 01 12` ::: `seq -w 01 31`
real 4m16,726s
user 0m10,219s
sys 0m14,942s
# 20 cores per wget url
juan@mediacenter:~/elsotanillo$ rm *
juan@mediacenter:~/elsotanillo$ time parallel -j20 wget -q https://www.elsotanillo.net/wp-content/uploads/parallel/{1}{2}{3}.txt.gz ::: `seq -w 16 20` ::: `seq -w 01 12` ::: `seq -w 01 31`
real 3m47,145s
user 0m10,116s
sys 0m14,908s
# 100 cores per wget url
juan@mediacenter:~/elsotanillo$ rm *
juan@mediacenter:~/elsotanillo$ time parallel -j100 wget -q https://www.elsotanillo.net/wp-content/uploads/parallel/{1}{2}{3}.txt.gz ::: `seq -w 16 20` ::: `seq -w 01 12` ::: `seq -w 01 31`
real 3m36,614s
user 0m10,114s
sys 0m16,307s
We might think that the optimum parallelization number should be 4, 1 job per core, but downloading is no not a high CPU consuming task therefore each core can manage several downloading task without affecting performance. In fact the network throughput is slightly better using 100 jobs (20 jobs per core).
| Number of Jobs | Time | Speed |
| 1 | 5m4,776s | 16.73 kB/s |
| 4 | 4m29,554s | 18.92 kB/s |
| 8 | 4m22,665s | 19.42 kB/s |
| 12 | 4m5,267s | 20.79 kB/s |
| 16 | 4m16,726s | 19.87 kB/s |
| 20 | 3m47,145s | 22.45 kB/s |
| 100 | 3m36,614s | 23.54 kB/s |
There is some improvement but still sucks
Conclusions about downloading serial vs parallel
We can see that downloading the files in parallel (using 4 jobs) is around 1.13 times better and with the optimum number of jobs (100) the ratio is around 1.4.
Downloading a bunch of small files sucks. Why is that? you might guess
TCP has a congestion protocol in place that uses a slow start to avoid network problems. From https://blog.stackpath.com/tcp-slow-start/:
TCP slow start is an algorithm which balances the speed of a network connection. Slow start gradually increases the amount of data transmitted until it finds the network’s maximum carrying capacity.
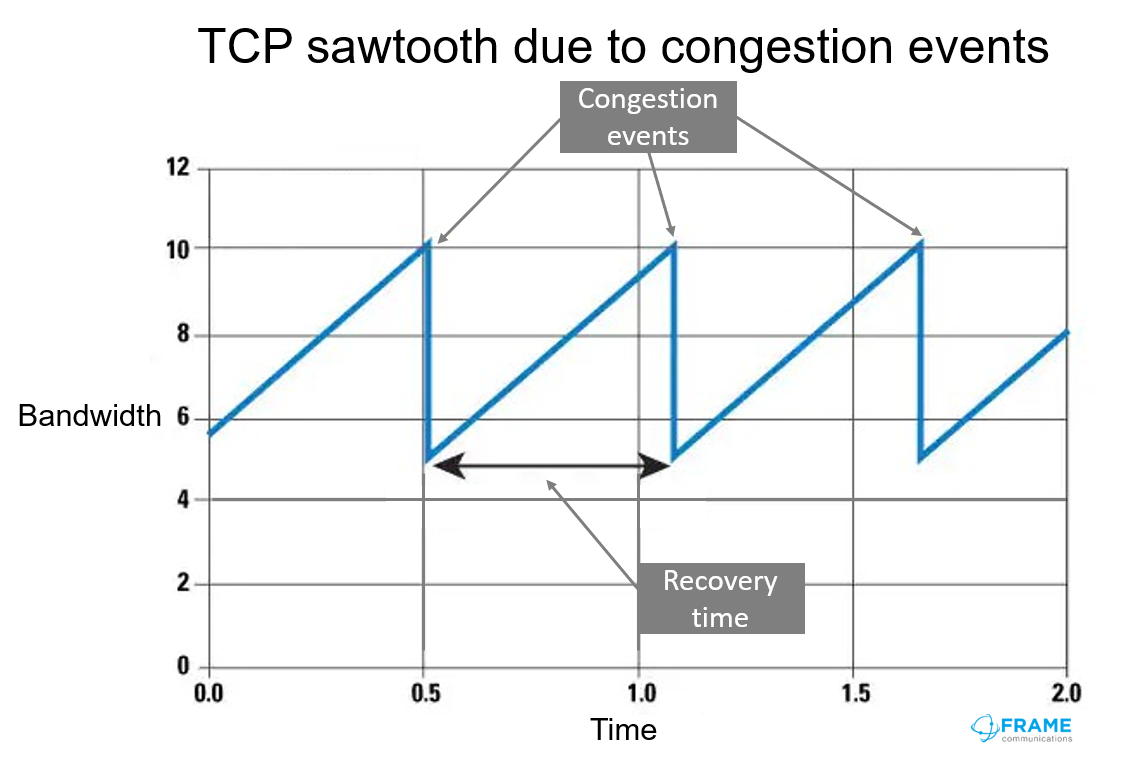
https://frame.co.uk/use-cases/understanding-tcp-and-the-need-for-tcp-acceleration/
The reason that the average is so poor is that in a serial download we are always at the very beginning of the graph.
While parallelizing the downloads we are overlapping several on these figures giving a total throughput that is the sum of all the figures at a given time. Something similar to the following plot: (thanks old good GnuOctave)
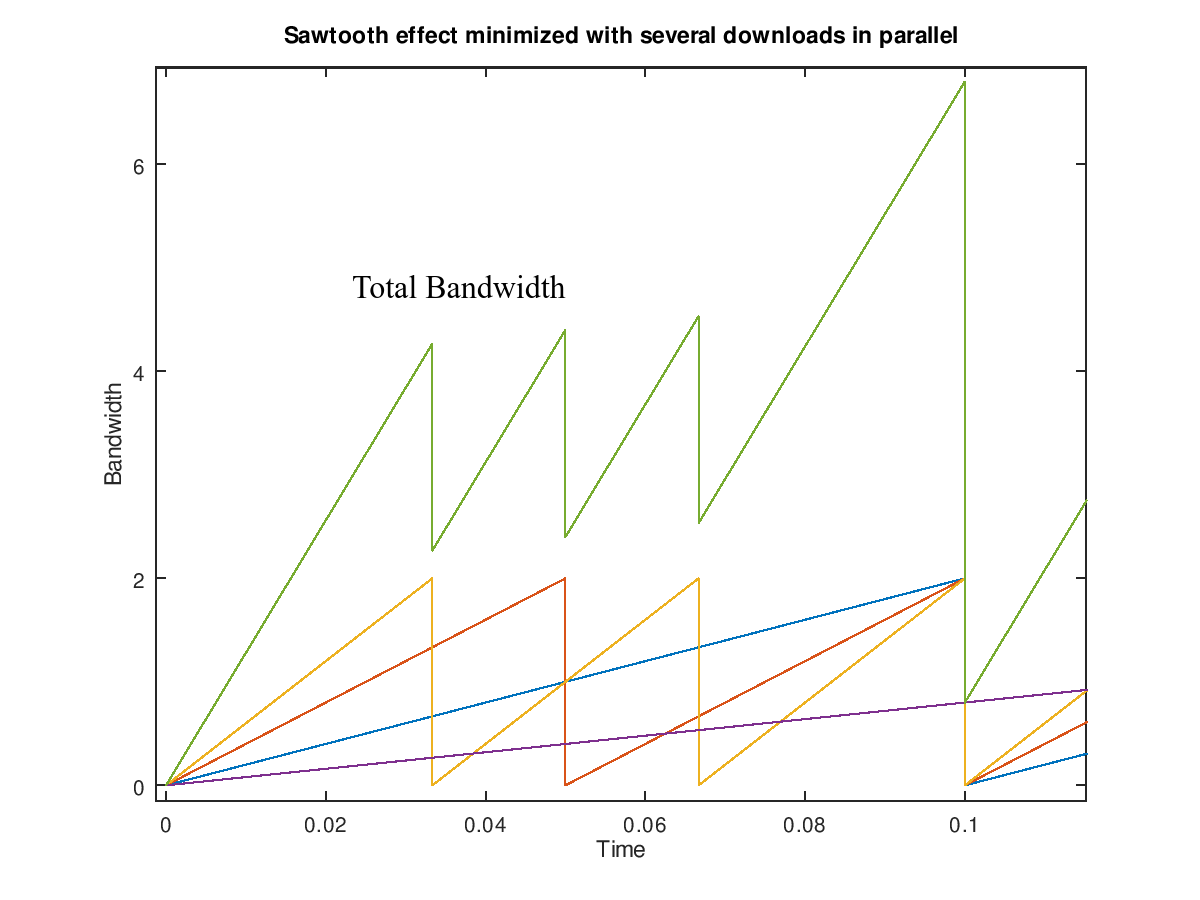
Sawtooth effect with parallel downloads
Parallelization helps but it is not the solution for this use case.
Is there room for improvement?
We have missed a point variable from the equation. The cost of each TCP new connection. TCP implements a 3-ways handshake process meaning we are doing this 3-ways handshake per each file. Wget supports reusing the HTTP connection (via Keep-Alive mechanic) so no new TCP conection has to be created per file. In order to test this we can generate a file (urls.txt) with all the URLs and feed this file to the wget command.
parallel -j1 echo https://www.elsotanillo.net/wp-content/uploads/parallel/{1}{2}{3}.txt.gz >urls.txt ::: `seq -w 16 20` ::: `seq -w 01 12` ::: `seq -w 01 31`
Let test this new approach:
juan@mediacenter:~/elsotanillo$ time cat urls.txt | parallel -j1 -m wget -q {}
real 1m44,444s
user 0m0,714s
sys 0m0,564s
So reusing the connection in serial mode performs 2.91 times better that the baseline. Now is time to use some parallelization degree:
juan@mediacenter:~/elsotanillo$ time cat urls.txt | parallel -j4 -m wget -q {}
real 1m1,231s
user 0m0,606s
sys 0m0,675s
Reusing the connection and launching 4 jobs in parallel performs 4.97 times better. For this specific case there is no real improvement using more than 4 jobs in parallel.
Regarding the -m option used in parallel helps us to use as much as urls in the wget command line.
-m Multiple arguments. Insert as many arguments as the command line length permits. If multiple jobs are being run in parallel: distribute the arguments evenly among the
jobs. Use -j1 or --xargs to avoid this.
Again: Is there any room for improvement?
Not at client level that I am aware of. But knowing that the problem was the throughput there is something that we can do. Even with the parallel approach some of the bandwidth is still wasted.
Gzip files can be concatenated in a bigger file. Let’s make a bigger file and see how it goes. With the cat command in the server, we can create on bigger file.
[...]
160603.txt.gz 161101.txt.gz 170331.txt.gz 170901.txt.gz 180202.txt.gz 180706.txt.gz 181204.txt.gz 190510.txt.gz 191008.txt.gz 200310.txt.gz 200813.txt.gz
root@do1:/var/www/html/elsotanillo.net/wp/wp-content/uploads/parallel# find . -type f|wc -l
1276
root@do1:/var/www/html/elsotanillo.net/wp/wp-content/uploads/parallel# du -sh
5.1M .
root@do1:/var/www/html/elsotanillo.net/wp/wp-content/uploads/parallel# cat *.txt.gz > total.gz
root@do1:/var/www/html/elsotanillo.net/wp/wp-content/uploads/parallel# ls -lh total.gz
-rw-r--r-- 1 root root 3,0M jun 8 19:55 total.gz
Pay attention to this: 1276 gzipped files are 5.1Mbytes and the concatenated version of them is only 3.0Mbytes. This difference is caused by how the Operating System saves the file and the filesystem’s block size. Both approaches the bunch of files and the bigger file contain the same data. This can be corroborated by counting the number of lines for all the files and for the big file:
juan@mediacenter:~/elsotanillo$ zcat *.txt.gz|wc -l
183912
juan@mediacenter:~/elsotanillo$ zcat total.gz|wc -l
183912
By choosing the right file format we have reduced the data to be transferred by 1.7. Chose your data format carefully. In the previous post, we saved a lot of time by choosing gz files instead zip files. Remember .gz files allowed us to avoiding writing to disk.
Let’s download this big file:
juan@mediacenter:~/elsotanillo$ time wget -q https://www.elsotanillo.net/wp-content/uploads/parallel/total.gz
real 0m2,179s
user 0m0,000s
sys 0m0,067s
WOW!!! this is serious stuff only 2,179s. Let’s put all in a nice table
Pay attention that this last one-liner is also a serial one. Downloading a bigger file performs even better that the parallel approach.
| Approach | Time | Ratio (improvement) |
| Serial | 5m4,776s | 1 (baseline) |
| Parallel (100 jobs) | 3m36,614s | 1.4 |
| Serial (with url.txt) | 1m44,444s | 2.91 |
| Parallel (with url.txt and 4 jobs) | 1m1,231 | 4.97 |
| Bigger file | 0m2,179s | 139.87 |
So the knowing your stuff approach performs 139.87 time better than the baseline (serial one).
Now imagine that instead of a thousand small files like in this PoC you have hundred or thousand million of very small files and you can (with your boss help like in the previous post) get them concatenated in bigger files and processed in parallel. The resource saving could be astronomical:
- Less Network congestion
- Less disk storage
- Less electricity consumption
- More near real-time apps
- More happy customers
Conclusion
Knowing your stuff means:
- Select the best data format to use as input for your processes. We have seen that the right format can:
- Reduce the amount of data to transfer
- Allow us to do the task without writing to disk
- Show your numbers to the decision makers. Help them negotiate with the data providers about the right format to be delivered.
- Ensure you understand how network works.
- Ensure you understand how parallelization can help you. Parallelization per se is not the solution.
- Get the data as soon as possible to your cores and keep feeding them 🙂
- And from the previous post:
- Do not write to disk
- If if is necessary write to the disk use the buff/cache properly
Adding just more resources (SSD disks, RAM, etc) is not the solution if they are not being used efficiently
To be continued…
In the coming post (and last post) I am going to do the thousand small files with the serial/parallel approach and writing/avoiding disk IO to see the improvement ratio. I am curious….
Already on the air: Optimizing long batch processes or ETL by using buff/cache properly III (full workflow)
A word of niceness:
Remember to be nice with your network colleagues. Wget supports a rate limit option. Divide the total throughput you want to achieve per the number of jobs your are going to use. Make their life easier 🙂
–limit-rate=amount
Limit the download speed to amount bytes per second. Amount may be expressed in bytes, kilobytes with the k suffix, or megabytes with the m suffix. For example,
–limit-rate=20k will limit the retrieval rate to 20KB/s. This is useful when, for whatever reason, you don’t want Wget to consume the entire available.